For many years, the telecoms industry has been promoting digital transformation across various fields. However, from the perspective of the telecoms industry, although we are running the most advanced network in the world, a large number of operations and maintenance methods are still in a ‘manual phase’ that we might think belongs to the eighteenth century, leading to structured problems.
First, in terms of financial results, opex investment is generally three to four times higher than that of capex. In addition, network construction optimization makes it difficult to enable operators to improve their financial status on a large scale.
Second, the complexity caused by the overlay of multi-generation networks poses great challenges in manual operations for operation personnel. Numerous problems with sites, pipelines, and equipment rooms form physical breakpoints that hinder automation. The complexity of core systems made manual operations difficult and led to 70% of network-level accidents.
Third, the structural shock of the internet not only poses threats to cloud services, but also to networks. The impact of this is seen from DC backbone networks to cloud-network-synergy enterprises networks. It is affecting the cloud-network-synergy market with large scale, wide coverage, high utilisation, and deep data integration.
In terms of opex distribution, we can further review the challenges facing the telecoms industry from four aspects: operation (maintenance and employees), energy (power, water, electricity, and heating), resource utilisation (circuit NE leasing, depreciation, and website interconnection), and experience (sales expense and product costs).
First, from the perspective of operation efficiency, one major characteristic is heavy routine workloads. Taking an operator as an example, the annual number of office data records exceeds 17 billion pieces, those of NE parameters stands around 10 million, those of transmission risk elimination is nearly 1 million, and those of maintenance for home broadband communities is tens of thousands. Physical facilities are of great importance.
According to the work order survey in a region, 26% of work orders are related to feeder or optical fibre problems, 26% to restoration operations such as restarting non-master equipment software, 24% to automatic recovery after mains supply interruptions, 11% to automatic alarm clearing, and just 10% to faults on device hardware.
The second characteristic is that the network cutovers and upgrades must be performed more than 100,000 times each year, and the emergency assurances nearly 400,000 times. Therefore, a large amount of manpower is required to ensure these upgrades and major events.
Second, site energy consumption (including outdoor sites and telecoms equipment rooms) affects 60% to 80% of energy efficiency issues, while data centres affect around 20%. Energy consumption will continue to rise in the cloud-enabled data centres.
From the perspective of operation statistics, traffic distribution is unbalanced in time and space. The busiest top 10% of sites of a network generate 50% of the traffic, while the idlest 50% sites generate only 5% traffic. However, the basic energy consumption of these sites is the same. That is, sites generating little or low traffic still consume a large amount of energy.
Third, from the perspective of resource utilisation, the root cause of low resource utilisation is an unbalanced distribution of service traffic in time and space. In addition, resources are limited by physically distributed design and operation, and do not adopt the global centralised design and dynamic scheduling with time and space. For example, the backbone network usage of operators is about 30%.
Traditional traffic optimisation and optimisation strategies (such as optimisation triggering threshold and migration traffic selection) do not support dynamic adjustment based on the application and network traffic status. Therefore, continuous load balancing is not possible, lagging far behind internet companies with around 90% network utilisation.
Finally, from the perspective of customer experience, there are still many manual operation activities such as traditional drive tests and neighbouring cell parameter optimisation. The sampling test cannot comprehensively and objectively reflect the customer experience, and the multi-source dynamic data of terminals, applications, and time and space is not introduced, which cannot fully drive automatic network adjustment.
Use architecture innovations to resolve issues
Architecture innovations solve the structured problems for the telecom industry. The combinations of innovations in products, business models, and systems enable automatic, self-healing, self-optimized, autonomous networks, as well as digital service operations. This makes breakthroughs in operation, energy, resource utilization, and service experience.
Based on the service process of operators, analyse the activity distribution, cost distribution, and manpower distribution in terms of planning, design, deployment, provisioning, operation, and optimisation, and innovate the architecture to achieve the automatic goal. In the case of high failure rate of passive devices such as cables, power supply, and environment, the objective of “active devices manage passive devices” is put forward. That is, active devices can be used to predict and manage passive devices.
To solve the problem that the network has power consumption with no traffic, the “bits drive watts” objective is put forward. Only when there is bit flow, there is watt consumption. The time-space multiplexing objective is proposed to maximise the reuse of network capacity in the case of unbalanced traffic in time and space. According to the characteristics of rich terminal applications and full-process experience, the goal of “application-driven experience improvement” is proposed to introduce more terminal application elements and drive automatic network adjustment based on experience results. The breakthroughs are extracted from use cases, forming a series of value points. We can combine the value points into solutions to facilitate business scenario improvement.
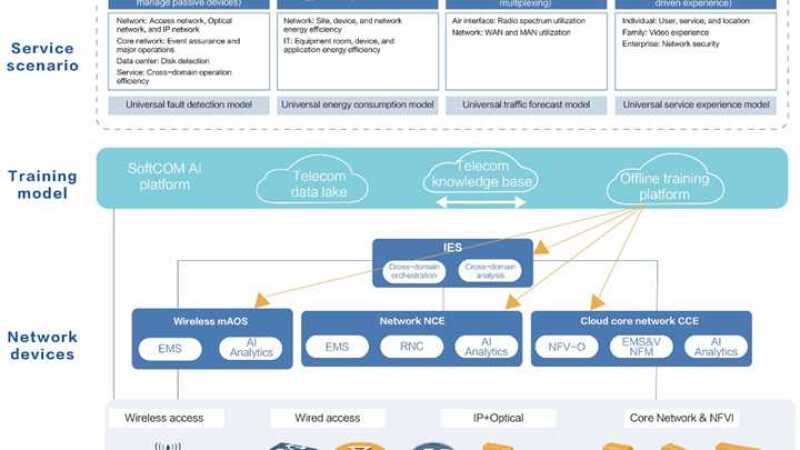
On the training platform, Huawei focuses on building an AI training platform oriented to the telecom field. The training platform is deployed in public cloud + stack mode. The stack mode can be extended to operator’s network deployment, so that the training can be completed without data transmission. The training platform provides the AI tool chain and common model services in the telecom domain.
A telecoms data lake is composed of the basic data, lab test data, field data, and marking data generated during service operation of network products, as well as the running data of typical sample network devices that are desensitised. The data lake is used for continuous training. Service 2.0 in the network field aims to provide online digital smart services and AI-based online services. This type of services is under continuous iteration and operate in “model as a service” mode by following industry practices. The services are always in the beta phase and constantly updating and improving. The telecom model is continuously released to the model market for iterative update and optimisation.
At the network and device level, the goal is to build an agile and intelligent network. Three capabilities are introduced to the bottom-layer devices and cloud infrastructure, middle-layer network management and control, and upper-layer entire process system to achieve network autonomy.
The first capability is device digitalisation. On the basis of large capacity, low latency, and high availability, we can enhance the data collection and parsing capability of a dynamic awareness environment, including the awareness of the surrounding environment and passive devices.
Typical scenarios include the perception of the antenna status in the wireless field, the perception of optical fibres, signals, and routes in the network field, the dynamic and on-demand processing of large-scale distributed streaming data in the IP domain, and the real-time and dynamic restoration of the network topology. The perception and digitalisation capabilities of these networks and devices are the basis of network automation and intelligence.
The second capability is inference execution based on the AI model. The network and devices can perform inference execution based on the AI model, including data preprocessing and AI model management. The process of inference execution must ensure network security and robustness, and the deployment can be divided into embedded deployment, network management and control integration, independent deployment, or public cloud service deployment.
The third capability is the service process orchestration capability. The telecom domain model works with the local business process of operators. Digital technologies such as model-driven, process orchestration, data analysis, and AI are used to implement automatic service provisioning and automatic service/network operation, helping achieve the real time, on demand, all online, DIY, social (ROADS) experience.
For the optical networks, we can learn how AI promotes the entire service process: In terms of service scenarios, we need to find specific scenarios, such as automatic fibre check, service provisioning, network optimisation, fault location, and automatic resource scheduling, and determine the breakthrough points to aligning with the need of “zero wait time, contact-free operation, and zero negative feedback”.
The training platform provides the data and artificial intelligence algorithms that best suit the telecoms field, including optical module data, lab fibre bending, loose, grey, and live-network fault data. Algorithms include basic data cleaning, information integration, machine learning modelling, and in-depth learning.
The optical fibre fault model and filter model are jointly trained. The management and control platform is combined with the live network to implement quick provisioning, simplified operation, and intelligent operation. The basis of this is to add data collection and parsing capabilities at the network device layer, including the capability of collecting fibre data, optical signal data, and routing data. In addition, the equipment must have reliable inference execution capabilities.
Objectives: improved operations, efficient energy, high resource utilisation, and optimal service experience
Operation level has three phases. The first phase is run-to-failure (R2F), where operation personnel must go and handle faults in networks as quickly as possible. The second phase is preventive maintenance (PvM), where all devices are checked to prevent faults, leading to inefficient services. The third phase is predictable maintenance (PdM), where the fault probability is predicted, and maintenance is done based on the status.
In Autonomous Network and Service 2.0, devices are used to implement site management through network simplification. This reduces faults in passive devices such as power supplies, connectors, and cables. In addition, active management is adopted to manage passive devices, such as cables, connectors, and power environments.
For example, route, fibre, and signal visualisation are enabled to allow optical fibres to predict and locate problems, such as fibre aging, excessive bending, loose connectors, and long routes, based on status. Intelligent fault prediction and network design enable shared network loads, and transforms repair and inspection into predictive maintenance based on status. Then, manual open loop becomes device-based closed loop, which achieves automatic recovery for non-physical faults and improving operation efficiency.
In terms of energy efficiency, we adopt the “bits drive watts” strategy, where network traffic determines power consumption. Power consumption is reduced when there is no traffic, and AI can predict traffic and adjust the energy efficiency of operator sites and data centres in real time to save energy. Site auxiliary facilities are incorporated into equipment cabinets to maximize site energy efficiency. Service traffic is accurately predicted and devices are quickly put into deep sleep mode, realising the “bits drive watts” strategy and ensuring energy consumption management with optimal customer experience.
In data centres, equipment rooms, and sites, each system has dozens of parameters. Through AI training, Autonomous Network and Service 2.0 generates heat dissipation, environment, and service load models to achieve optimal energy efficiency for auxiliary facilities. These include diesel generators, solar energy, and batteries that operate with the proper amount of sunlight and under proper temperatures. In addition, it finds optimal modes for dozens of pieces of water cooling equipment.
At the equipment layer, dynamic energy distribution can be performed according to service workloads. When there is no traffic, power consumption is reduced through timeslot shutdown, RF deep sleep, and carrier shutdown. In addition, dynamic energy-saving management of data center objects (such as server components) is implemented. At the network system layer, an accurate service load prediction model is constructed for optimal traffic scheduling on networks, improving energy consumption efficiency.
Autonomous Network and Service 2.0 can accurately predict long-period traffic rules, ensuring the optimal utilisation of sites, pipelines, and equipment rooms. The air interface spectrum is maximised based on the distribution of users, terminals, and services. Balanced elastic traffic during peak and off-peak hours improves the utilisation of the backbone networks to full-load operations. Based on the identification of service and traffic features (proximity, periodicity, trends, and events), trend prediction, and path performance prediction, traffic is dynamically allocated and balanced during peak and off-peak hours, greatly improving network utilisation. Traffic paths can be adjusted, almost in real time, to achieve optimisation without compromising QoS or SLA.
With automatic closed loop networks, Autonomous Network and Service 2.0 introduces user data to terminals and applications, achieving optimal user experience. Corporate users can construct cloud-and-network synergy in minutes, coordinate global networks across multiple regions, and implement automatic forwarding and learning on networks. This allows them to achieve user-transparent scheduling and routing. Cloud synergy is deployed at the home user end to improve the home broadband quality, user experience, and problem handling efficiency of home networks.
Implementation path of Autonomous Network and Service 2.0
The automatic running of the network must be a long-term process. We must have a clear long-term goal as a guide and bear in mind that the automation cannot be achieved overnight. We need to start with the end in mind, forging ahead with small steps, and make achievements along the way.
We can divide network autonomy into five levels. Level 0 is manual operation and maintenance. Level 1 is auxiliary operation. The system can continuously control a subtask, such as board switchover and automatic rerouting.
Level 2 is a partial autonomous network. Under the applicable design scope, the system can perform some unit control tasks according to the AI model or rules. For example, the data center can automatically adjust the parameters of the water-cooled equipment unit based on training models. In this way, energy efficiency can be improved and PUE can be reduced. However, dynamic prediction and adjustment are limited in a certain unit.
Level 3 is conditional autonomous network that can implement complete closed-loop automation at the subsystem level. Taking the wireless domain as an example, this solution can be used to evaluate and predict user traffic, perform resource scheduling and parameter adjustment over the air interface, and assess the network adjustment effect. Automation can be achieved from perception, decision-making, execution, and after-event evaluation.
Level 4 is a highly autonomous network. The system can automate the entire life cycle of a single service across domains, such as cloud VPN service design, deployment and provisioning, dynamic scheduling, and automatic fault self-healing.
Level 5 is a fully autonomous network. The system can perform complete dynamic tasks in all network environments and handle exceptions properly.
Network autonomy is a step-to-step process, from providing an alternative to repetitive execution actions, to performing perception and monitoring of network environment and network device status, making decisions based on multiple factors and policies, and providing effective perception of end user experience. The system capability also starts from some service scenarios and covers all service scenarios.
The network autonomy and service 2.0 model has a long way to go. Huawei launches SoftCOM AI, relying on Huawei’s long-term and resolute strategic investment in All Intelligence, digital and intelligent network and device investment, and continuous investment in digital practices in the service field and in platform construction. Huawei is determined to build an autonomous network solution, upgrade the service mode, and release a series of solutions. Network autonomy is like automatic driving. It requires a rich ecosystem of partners to inject operation and maintenance experience into the system and work together to achieve automatic, self-healing, self-optimization, autonomous networks, and digital operation of services.